
Generative AI for Smart Homes: Prompts to Control Your IoT Devices in 2026
October 7, 2025
Prompt Engineering for AI Voice Agents: Creating Natural Conversations
October 14, 2025
✍️ Introduction: Beyond Words in the AI Era
For years, AI prompting has largely meant typing text into models like ChatGPT, Claude, or Gemini. But the next leap is already here: multi-modal prompting. With GPT-5 and similar next-gen AIs, we’re no longer limited to text — these models can now interpret and generate across images, audio, and even video.
This means developers, creators, and productivity enthusiasts can orchestrate entire workflows across media formats, opening up new possibilities in design, communication, and automation.
If you’ve ever wished you could:
- Upload a sketch and have AI turn it into code.
- Feed a video clip and ask AI to summarize key insights.
- Use voice commands to direct complex workflows.
…then multi-modal prompting is the frontier you’ve been waiting for.

📚 What is Multi-Modal Prompting?
Multi-modal prompting is the process of interacting with AI using multiple forms of input — not just text. With models like GPT-5 and beyond, prompts can include:
- 📝 Text: Traditional instructions and queries.
- 🖼️ Images: Diagrams, sketches, or photos.
- 🎙️ Audio: Voice instructions or sound clips.
- 🎬 Video: Dynamic content for summarization or analysis.
Instead of treating each medium separately, multi-modal AIs blend context from different formats, providing richer, more accurate responses.
💡 Why Multi-Modal Prompting Matters
Multi-modal prompting enhances workflows in several key ways:
- Contextual Understanding: AI can interpret complex inputs (e.g., combining a photo of a product with a text-based design spec).
- Accessibility: Voice and image prompts make AI usable for people beyond traditional text typers.
- Efficiency: Instead of long written descriptions, simply show or record what you mean.
- Creativity: Open new possibilities for design, storytelling, and prototyping.
According to OpenAI, multi-modal models are paving the way for AI systems that can reason more like humans — integrating sight, sound, and language seamlessly.
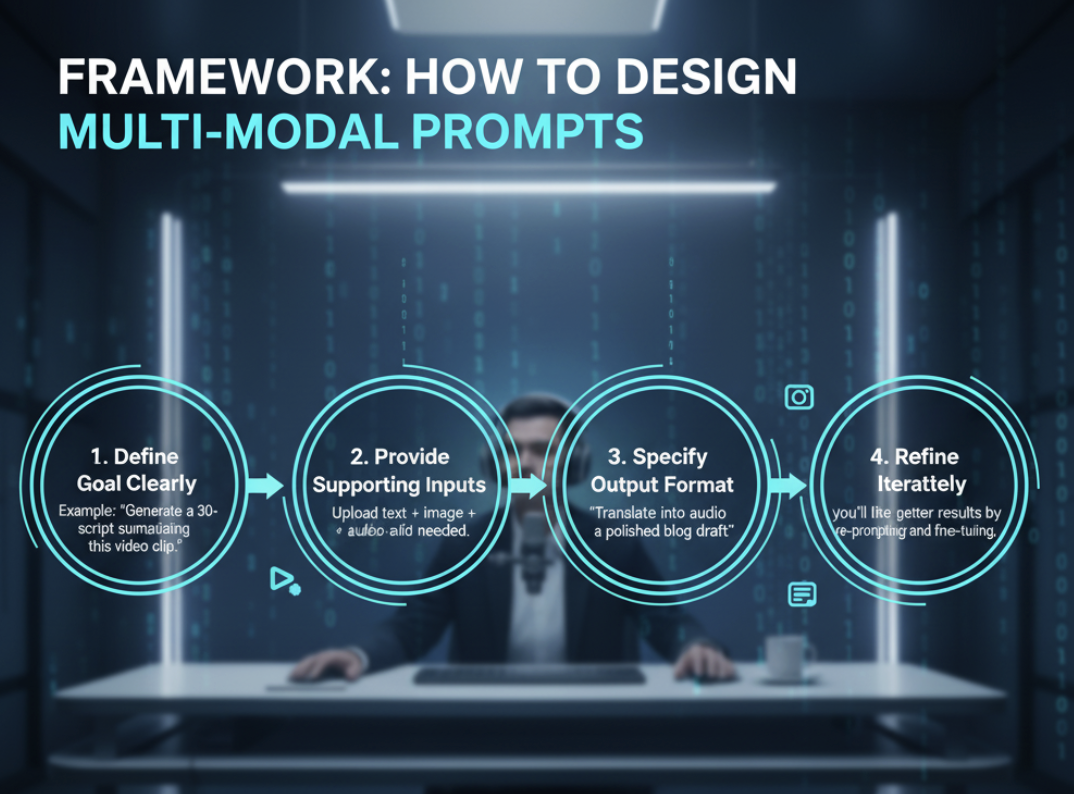
🛠 Framework: How to Design Multi-Modal Prompts
When crafting multi-modal prompts, clarity and structure remain key. Here’s a simple framework:
1. Define the Goal Clearly
- Example: “Generate a 30-second script summarizing this video clip.”
2. Provide Supporting Inputs
- Upload text + image + audio if needed.
3. Specify Output Format
- “Summarize into bullet points.”
- “Translate this audio into a polished blog draft.”
4. Refine Iteratively
- Just like text prompts, you’ll get better results by re-prompting and fine-tuning.
Checklist for better multi-modal prompts:
- ✅ Use multiple media only if it adds clarity.
- ✅ Label your inputs clearly (e.g., “Image A: Product design sketch”).
- ✅ Guide the output with structure (tables, slides, scripts).
🚀 Use Cases for Multi-Modal Prompting
Multi-modal prompting is already reshaping industries:
- Product Design: Upload sketches + text notes → AI generates prototypes.
- Marketing: Feed images, headlines, and voice notes → AI builds campaigns.
- Education: Combine a video lecture + transcript → AI makes quizzes.
- Healthcare: Input X-rays + symptoms → AI provides structured insights.
🔑 How My Magic Prompt Helps
While GPT-5 and other models offer multi-modal capabilities, crafting effective prompts is still a skill. This is where My Magic Prompt becomes your edge.
- 🧩 Prompt Builder: Create structured prompts for text, image, and audio.
- 📚 Prompt Templates: Ready-made frameworks for multi-modal workflows.
- ⚡ AI Toolkit: Manage, save, and reuse your best prompts.
- 🌐 Browser Extension: Magic Prompt Chrome Extension for fast prompting on the fly.
By using My Magic Prompt, you’re not just prompting smarter — you’re orchestrating across media seamlessly.
❓ FAQ: Multi-Modal Prompting Explained
1. What’s the difference between text-only and multi-modal prompting?
Text-only prompting uses words alone, while multi-modal combines text with images, audio, or video for richer results.
2. Can GPT-5 handle video input directly?
Yes, models like GPT-5 can process video frames alongside text to summarize or generate insights.
3. How do I organize my prompts for multi-modal workflows?
Use tools like My Magic Prompt to save templates and structure inputs.
4. Are multi-modal prompts harder to design?
Not necessarily — they require clear labeling of inputs, but the process is similar to text prompting.
5. What industries benefit most from multi-modal AI?
Design, healthcare, education, marketing, and entertainment are leading adopters.
6. Can I use multi-modal prompts with free AI tools?
Some platforms are rolling out free trials, but advanced use often requires premium access.
🤍 Final Thoughts: The Future is Multi-Modal
We’re entering an era where words are no longer enough. To fully harness AI’s power, users must learn to prompt across text, visuals, audio, and video.
By combining best practices with the right tools, you can stay ahead of the curve and unlock workflows that feel almost magical.
Ready to explore smarter prompting? Try My Magic Prompt for structured templates and tools designed for the multi-modal future.